Conference Talks
Sharing insights on cloud infrastructure, Kubernetes, and site reliability engineering at industry events.

Scaling GPU Clusters for ML Workloads
Best practices for managing large-scale GPU infrastructure on Kubernetes for distributed machine learning training.
Achieving 99.97% Uptime at Scale
Strategies and lessons learned from maintaining high availability across multi-cloud infrastructure serving millions of users.
Terraform at Enterprise Scale
Managing infrastructure as code across multiple cloud providers with Terraform modules, workspaces, and automation.

GitOps for Multi-Cluster Kubernetes
Implementing GitOps workflows with ArgoCD for managing deployments across multiple Kubernetes clusters.

Cost Optimization: $8M Savings Journey
Real-world strategies for reducing cloud infrastructure costs while maintaining performance and reliability.
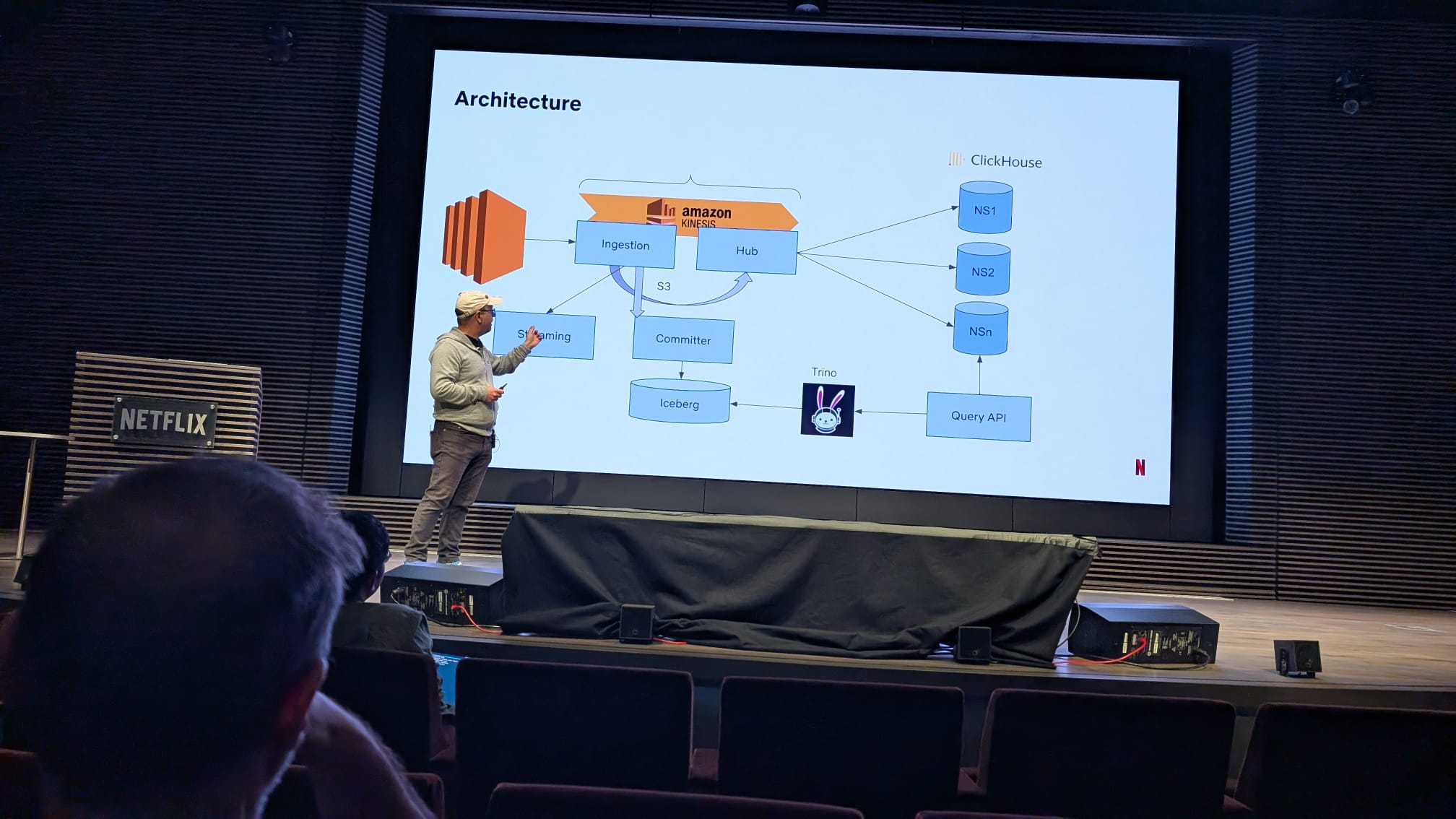
Building Internal Developer Platforms
Creating self-service platforms that accelerate developer productivity while maintaining governance and security.
View Full Resume
See my complete experience, certifications, and technical skills in detail.